高效存储的秘诀:bitmap 数据结构在标签中的应用 |
您所在的位置:网站首页 › bitmap 标签 › 高效存储的秘诀:bitmap 数据结构在标签中的应用 |
高效存储的秘诀:bitmap 数据结构在标签中的应用
|
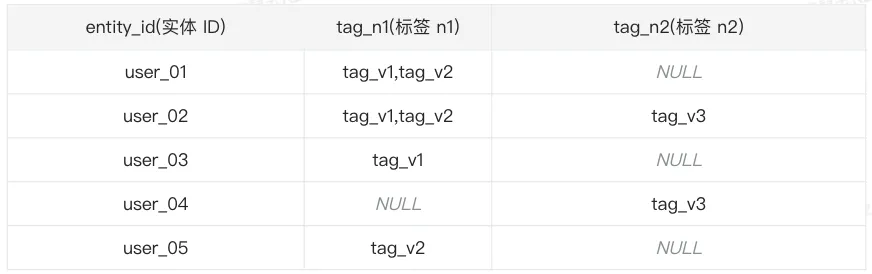
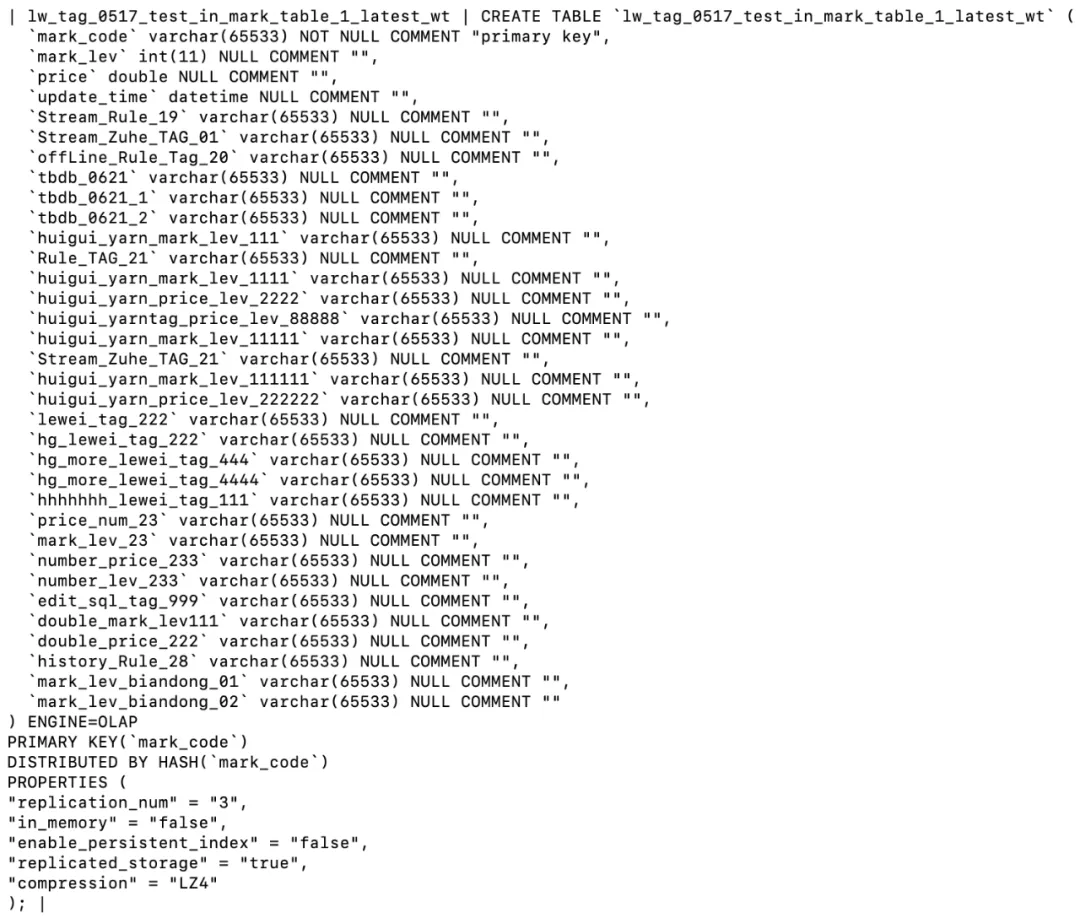
在当今大数据和信息爆炸的时代,如何有效地管理和查询海量的数据成为了企业和开发者面临的重大挑战。其中,标签系统作为数据管理中的一种重要手段,被广泛应用于用户画像、商品分类、内容推荐等多个场景。然而,随着标签数量的急剧增加,传统的数据存储和查询方式已难以满足高效率、低延迟的需求。在这种背景下,Bitmap 数据结构作为一种高效的位级数据处理技术,开始在标签系统中展现出其独特的优势。 通过本文将会分享 Bitmap 方案在标签中的应用实践。 标签和群组 标签标签用于描述一组具有相同特征的实体对象(例如实体可以是用户,对象就是具体的某一个人)。它能直接关联到具体的数据项、文档、产品、用户行为等,以实现快速检索、过滤和分类的目的。标签常被用于用户画像构建、行为分析以及个性化推荐,通过分析用户与标签的互动,系统能更精准地理解用户需求。 标签系统的核心在于通过简单直接的关键词关联,提高信息的可发现性和管理效率,适应数字化时代信息海量增长的需求。 群组群组提供了一种结构化的方式来整理和操作具有共同属性的标签集合,将具有相似特征、类别或关系的标签集合在一起,这种结构允许用户更高效地管理和操作相关联的标签集合,而不是单独处理每一个标签。 基于大宽表存储标签标签存储在大宽表中,每增加一个新的字段就会在大宽表中新增一个字段,此时基于标签的圈群计算会基于这张大宽表进行计算。
使用这种结构会重复存储大量的标签值,造成存储资源的浪费,例如上述表格中的 tag_v1 值在多个行中都有进行存储。在进行标签的圈群场景时效率不高,例如要统计具有 tag_n1 标签、标签值为 tag_v2 且具有 tag_n2 标签、标签值为 tag_v3 的实体 ID,此时 SQL 的运行效率较低。 基于 bitmap 数据结构存储标签bitmap 即为一个 bit 数组,一个 bit 的取值有两种:0 或 1。将一个数据状态较少的变量,转换为一个状态位 bit(只有0和1两种状态),存储到一个顺序的 bit 数组中,从而在海量数据中快速定位所需数据状态的数据。这种做法不仅节省内存空间,而且能够快速定位数据位置,在海量数据的排序、查询、去重相关处理中有极高的效率。
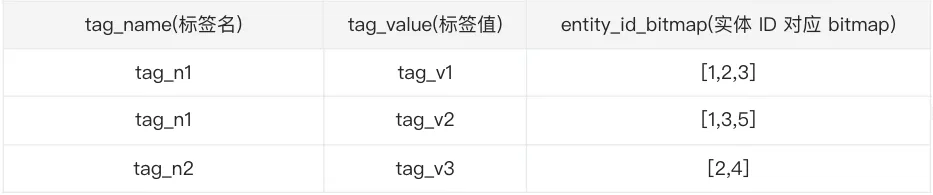
● 优化查询性能 由于数据以位的形式紧密排列,查询某个元素是否存在可以通过位运算直接完成,时间复杂度接近O(1),非常高效。使用 bitmap 可以在进行基数统计、唯一值计数等操作时显著提升效率,特别是在数据有大量重复且需要快速响应的场景下。例如,对于网站访问日志分析,bitmap 可以快速判断不同页面的独立访问者数量。 ● 空间效率较高 bitmap 利用每个比特位表示一个元素的状态(通常是存在或不存在),相比传统数组或列表,可以极大节省存储空间。例如,一个能存储 32 个整数的数组,在 Bitmap 中只需一个字节即可表示 32 个元素的状态。 ● 易于进行集合运算 bitmap 支持快速进行集合的交、并、差等运算,这对于处理数据间的关联查询非常有用。 ● 适用于统计 bitmap 能够快速进行计数操作,如统计集合中元素的数量,或统计满足特定条件的元素数量,常用于大数据分析和数据库索引中。 ● 适应连续性和稀疏性 bitmap 最适合用于表示大量连续整数或稀疏数据集中的元素存在性,对于非连续或随机分布的数据,其优势可能不那么明显。 在标签中如何使用 bitmap 数据类型对于标签来讲,一个实体 ID 和一个标签(标签名+标签值)的关系可以有两种——有这个标签和无这个标签。那么我们在设计标签结果表的时候就可以使用如下的表结构:
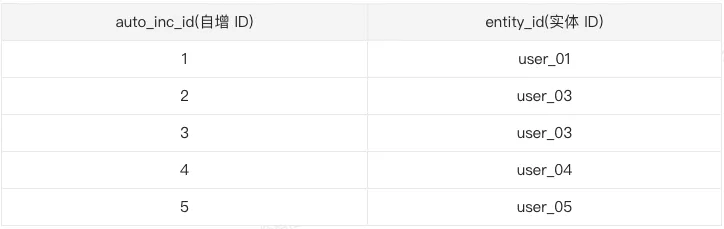
对比可以看到,使用 bitmap 数据结构在标签数量较小的情况下可以节省更多的存储资源。 entity_id_bitmap 数据结构为 bitmap,但是在大多数情况下实体 ID 的数据类型并不是数值类型的,可能为字符类型,由于 bitmap 只能直接支持整数类型,这就会导致无法将实体 ID 存入 bitmap 中,并且即使使用数值类型存储实体 ID,若不是自增类型的数值,可能会由于数据离散值太大,导致 bitmap 过长从而占用存储变大,所以需要将实体 ID 转化为自增的数值类型。 如何转化实体 ID 为自增数值类型使用一张中间映射表来维护自增 ID 和实体 ID 的关系,表结构示意如下:
auto_inc_id 字段使用自增列,entity_id 作为原始的实体主键,在每天标签任务开始运行前判断一下映射表中是否有实体主表中不存在的实体 ID,若存在则插入映射关系到映射表中。
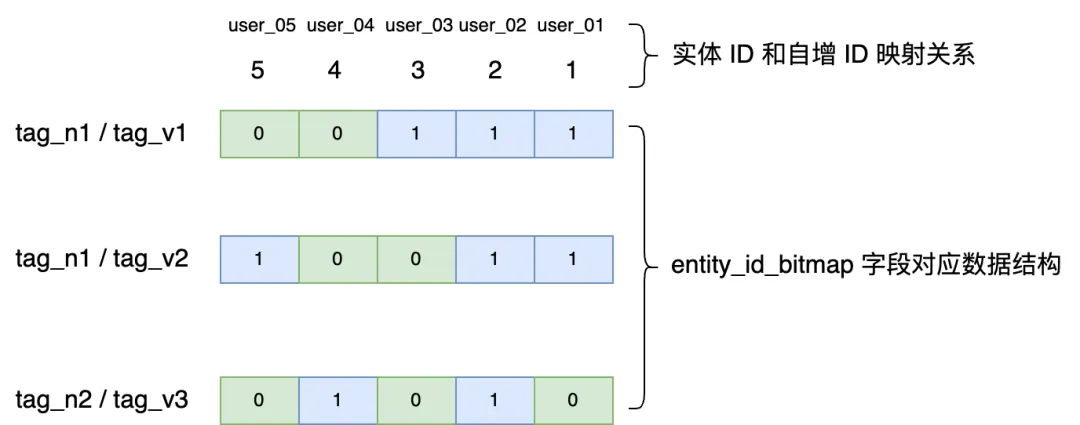
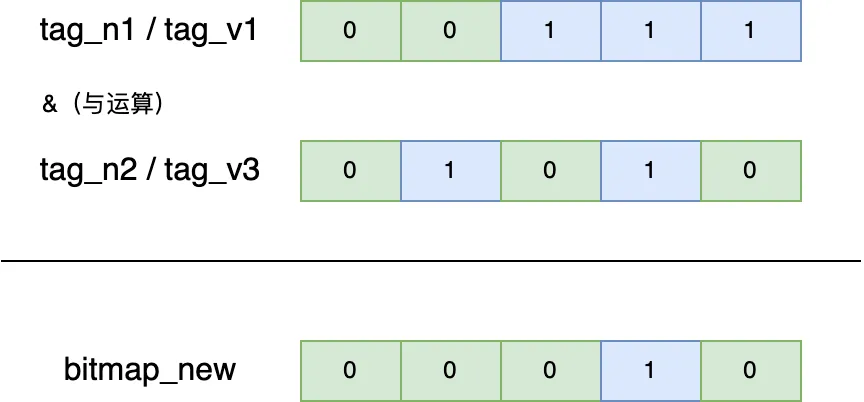
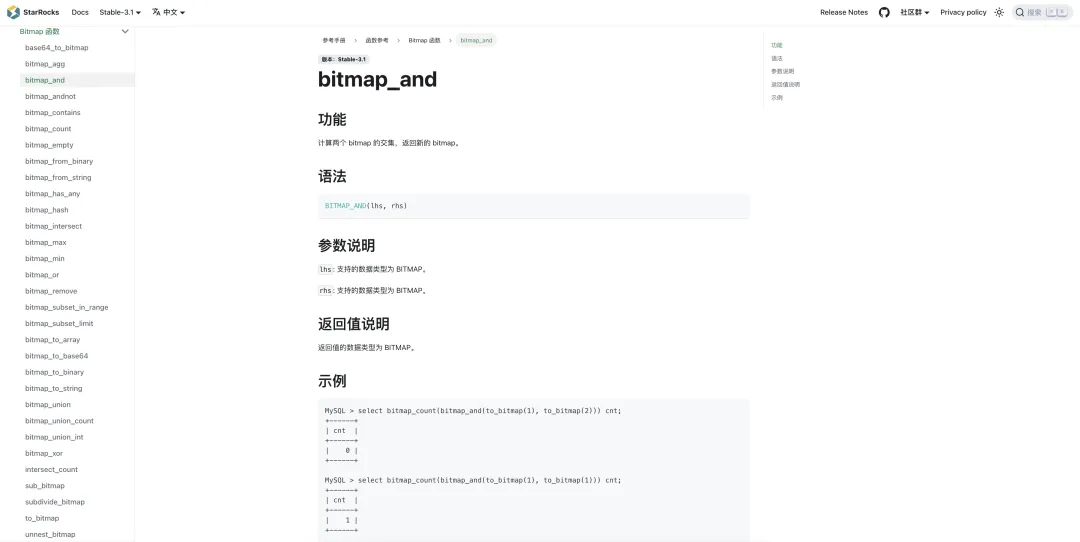
结合上述图标,如若需要计算拥有 tag_n1 标签、标签值为 tag_v1 且拥有 tag_n2 标签、标签值为 tag_v3 的实体 ID,转化为 bitmap 类型的处理,其实就是获取第一行 entity_id_bitmap 和 第三行 entity_id_bitmap 列的交集。 在 StarRocks 中提供了 bitmap_and 函数来计算两个 bitmap 的交集,底层计算逻辑大致如下:
计算得到自增 ID 为 2 的实体是符合要求的,对应的用户就是 user_02,此时就完成了简单标签圈群的场景计算,由于使用 bitmap 数据结构,底层计算使用位运算方式,计算效率相比使用大宽表的方式有了显著提升。 StarRocks bitmap 在标签平台的实践bitmap 在 StarRocks 中的典型应用场景包括但不限于用户行为分析、日志数据分析、实时报表生成等,特别是在需要快速进行去重计数和集合运算的场景。 「袋鼠云客户数据洞察」平台同时支持 Trino 和 StarRocks 计算引擎。在使用 StarRocks 引擎时,使用 bitmap 数据结构优化标签存储和标签圈群逻辑,相较于大宽表存储标签的方式,不仅节省了存储空间,而且在标签圈群方面大幅提升了圈群速度。 StarRocks 中自增列的使用方法:
StarRocks 提供了丰富的 bitmap 函数来支持集合操作,如交集、并集、差集等,相比 HyperLogLog(HLL),bitmap 可以提供更精确的计数结果,不过代价是更高的内存和磁盘资源消耗。
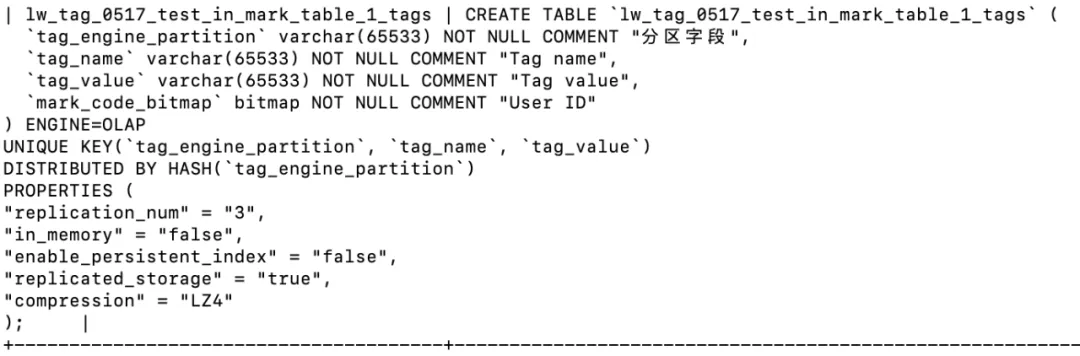
标签系统结果大宽表结构转为高表,群组结果表存储为 bitmap 类型的高表,圈群效果有所提升。
标签结果表结构对比如下: • 大宽表表结构
• 使用 bitmap 的高表表结构
使用 bitmap 的高表结构能有效减少空值列,减少宽表任务更新时长。 《行业指标体系白皮书》下载地址:https://www.dtstack.com/resources/1057?src=szsm 《数栈产品白皮书》下载地址:https://www.dtstack.com/resources/1004?src=szsm 《数据治理行业实践白皮书》下载地址:https://www.dtstack.com/resources/1001?src=szsm 想了解或咨询更多有关大数据产品、行业解决方案、客户案例的朋友,浏览袋鼠云官网:https://www.dtstack.com/?src=szbky |

【本文地址】
今日新闻 |
推荐新闻 |